
 |
1.基本特点
不可变性(Immutability):String对象一旦被创建,其值就不能被修改。任何对String对象的修改操作都会创建一个新的String对象。这是通过在内存中创建新的字符串来实现的,而不是在原有字符串上进行修改。
字符串常量池(String Pool):Java中的字符串池是一种特殊的内存区域,用于存储字符串常量。当创建一个字符串时,如果字符串池中已经存在相同内容的字符串,则直接返回池中的引用,而不会创建新的对象。
字符串连接:Java提供了多种方式来连接字符串,如使用"+"运算符、concat()方法、StringBuilder和StringBuffer类等。在频繁拼接大量字符串时,推荐使用StringBuilder或StringBuffer类,因为它们可以避免频繁创建新的String对象。
字符串比较:Java提供了多种方式来比较字符串,如使用equals()方法、compareTo()方法、equalsIgnoreCase()方法等。需要注意的是,在比较两个字符串时应使用equals()方法而不是"=="运算符。
字符串操作:String类提供了许多用于操作字符串的方法,如获取子串、查找字符或子串、替换字符或子串、转换大小写等。
字符串的编码:String类使用UTF-16编码来表示字符串,每个字符占用两个字节。可以使用getBytes()方法将字符串转换为字节数组,也可以使用构造函数将字节数组转换为字符串。
字符串的不可变性带来的优势:由于String对象不可变,可以在多线程环境下安全地共享。同时,由于不可变性,可以使用缓存和重用机制来提高性能。
2.字符串常量池
字符串常量池是Java中的一种特殊的内存区域,用于存储字符串常量。在Java中,当我们创建一个字符串常量时,编译器会将其放入字符串常量池中。如果字符串常量池中已经存在相同内容的字符串,则直接返回池中的引用,而不会创建新的对象。
String Pool是一个固定大小的Hashtable,默认值大小长度是1009。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降
节省内存空间:由于字符串常量池会检查是否已经存在相同内容的字符串,因此可以避免创建重复的对象。这样可以节省内存空间,特别是在频繁使用相同字符串的场景下。
字符串共享:由于字符串常量池中的对象是唯一的,多个引用可以共享同一个对象。这意味着多个变量可以引用相同内容的字符串对象,而不需要每次都创建新的对象。
字符串比较优化:由于字符串常量池中的对象是唯一的,我们可以使用"=="运算符来比较两个引用是否指向同一个对象。这样比较操作更加高效。
字符串字面值优化:在编译阶段,如果发现多个字面值相同的字符串常量,则只会在常量池中创建一个对象。这样可以减少运行时创建对象和比较操作
需要注意以下几点:
字符串常量池是在堆内存中的一部分,与堆中的其他对象分开存储。
字符串常量池是线程共享的,可以被多个线程同时访问。
通过调用String类的intern()方法,可以将堆中的字符串对象放入字符串常量池中,并返回常量池中该字符串对象的引用。
3.内存分配
常量池就类似一个Java系统级别提供的缓存。8种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种。
直接使用双引号声明出来的String对象会直接存储在常量池中。
如果不是用双引号声明的String对象,可以使用String提供的intern()方法。
String s1 = "abc";
String s2 = new String("def"); // 会创建两份,堆空间和字符串常量池
只要使用了intern方法 就会在字符串常量池中
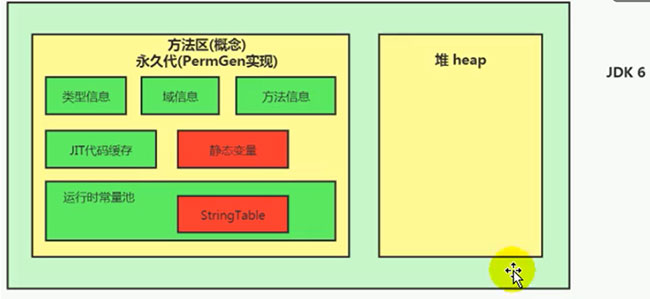
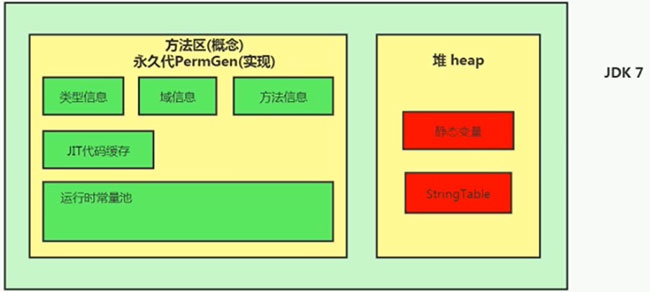
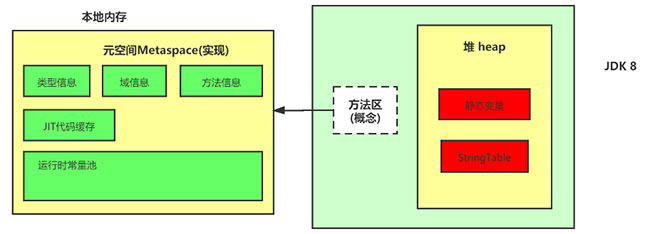
Java 6及以前,字符串常量池存放在永久代
Java 7中 Oracle的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到Java堆内
所有的字符串都保存在堆(Heap)中,和其他普通对象一样,这样可以让你在进行调优应用时仅需要调整堆大小就可以了。
字符串常量池概念原本使用得比较多,但是这个改动使得我们有足够的理由让我们重新考虑在Java 7中使用String.intern()。
StringTable为什么要调整?
官网地址:Java SE 7 Features and Enhancements (oracle.com)
Synopsis: In JDK 7, interned strings are no longer allocated in the permanent generation of the Java heap, but are instead allocated in the main part of the Java heap (known as the young and old generations), along with the other objects created by the application. This change will result in more data residing in the main Java heap, and less data in the permanent generation, and thus may require heap sizes to be adjusted. Most applications will see only relatively small differences in heap usage due to this change, but larger applications that load many classes or make heavy use of the String.intern() method will see more significant differences.
简介:在JDK 7中,内部字符串不再分配在Java堆的永久代中,而是分配在Java堆的主要部分(称为年轻代和老年代),与应用程序创建的其他对象一起。这种变化将导致更多的数据驻留在主Java堆中,而更少的数据在永久代中,因此可能需要调整堆的大小。大多数应用程序将看到由于这一变化而导致的堆使用的相对较小的差异,但加载许多类或大量使用String.intern()方法的大型应用程序将看到更明显的差异。
4.字符串拼接操作
常量与常量的拼接结果在常量池,原理是编译期优化
常量池中不会存在相同内容的变量
只要其中有一个是变量,结果就在堆中。变量拼接的原理是StringBuilder
如果拼接的结果调用intern()方法,则主动将常量池中还没有的字符串对象放入池中,并返回此对象地址
举例1:
public static void test1() {
// 都是常量,前端编译期会进行代码优化
// 通过idea直接看对应的反编译的class文件,会显示 String s1 = "abc"; 说明做了代码优化
String s1 = "a" + "b" + "c";
String s2 = "abc";
// true,有上述可知,s1和s2实际上指向字符串常量池中的同一个值
System.out.println(s1 == s2);
}
举例2
public static void test5() {
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true 编译期优化
System.out.println(s3 == s5); // false s1是变量,不能编译期优化
System.out.println(s3 == s6); // false s2是变量,不能编译期优化
System.out.println(s3 == s7); // false s1、s2都是变量
System.out.println(s5 == s6); // false s5、s6 不同的对象实例
System.out.println(s5 == s7); // false s5、s7 不同的对象实例
System.out.println(s6 == s7); // false s6、s7 不同的对象实例
String s8 = s6.intern();
System.out.println(s3 == s8); // true intern之后,s8和s3一样,指向字符串常量池中的"javaEEhadoop"
}
举例3
public void test6(){
String s0 = "beijing";
String s1 = "bei";
String s2 = "jing";
String s3 = s1 + s2;
System.out.println(s0 == s3); // false s3指向对象实例,s0指向字符串常量池中的"beijing"
String s7 = "shanxi";
final String s4 = "shan";
final String s5 = "xi";
String s6 = s4 + s5;
System.out.println(s6 == s7); // true s4和s5是final修饰的,编译期就能确定s6的值了
}
// 不使用final修饰,即为变量。如s3行的s1和s2,会通过new StringBuilder进行拼接
// 使用final修饰,即为常量。会在编译器进行代码优化。在实际开发中,能够使用final的,尽量使用
举例4
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3==s4);
}
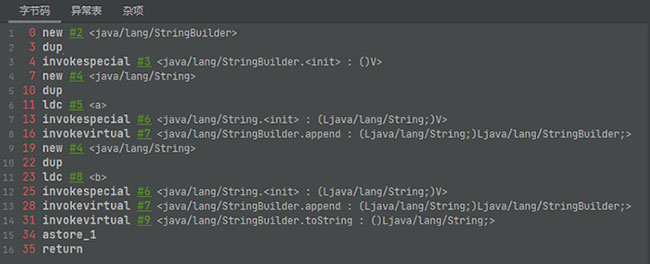
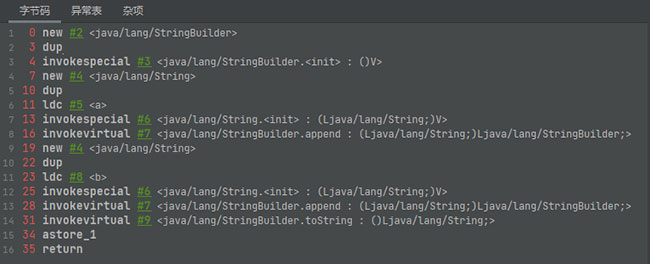
字节码
我们拿例4的字节码进行查看,可以发现s1 + s2实际上是new了一个StringBuilder对象,并使用了append方法将s1和s2添加进来,最后调用了toString方法赋给s4
0 ldc #2 <a>
2 astore_1
3 ldc #3 <b>
5 astore_2
6 ldc #4 <ab>
8 astore_3
9 new #5 <java/lang/StringBuilder>
12 dup
13 invokespecial #6 <java/lang/StringBuilder.<init>>
16 aload_1
17 invokevirtual #7 <java/lang/StringBuilder.append>
20 aload_2
21 invokevirtual #7 <java/lang/StringBuilder.append>
24 invokevirtual #8 <java/lang/StringBuilder.toString>
27 astore 4
29 getstatic #9 <java/lang/System.out>
32 aload_3
33 aload 4
35 if_acmpne 42 (+7)
38 iconst_1
39 goto 43 (+4)
42 iconst_0
43 invokevirtual #10 <java/io/PrintStream.println>
46 return
字符串拼接操作性能对比
public class Test
{
public static void main(String[] args) {
int times = 50000;
// String
long start = System.currentTimeMillis();
testString(times);
long end = System.currentTimeMillis();
System.out.println("String: " + (end-start) + "ms");
// StringBuilder
start = System.currentTimeMillis();
testStringBuilder(times);
end = System.currentTimeMillis();
System.out.println("StringBuilder: " + (end-start) + "ms");
// StringBuffer
start = System.currentTimeMillis();
testStringBuffer(times);
end = System.currentTimeMillis();
System.out.println("StringBuffer: " + (end-start) + "ms");
}
public static void testString(int times) {
String str = "";
for (int i = 0; i < times; i++) {
str += "test";
}
}
public static void testStringBuilder(int times) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < times; i++) {
sb.append("test");
}
}
public static void testStringBuffer(int times) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < times; i++) {
sb.append("test");
}
}
}
// 结果
String: 7963ms
StringBuilder: 1ms
StringBuffer: 4ms
结论
本实验进行5万次循环,String拼接方式的时间是StringBuilder.append方式的约8000倍,StringBuffer.append()方式的时间是StringBuilder.append()方式的约4倍
可以看到,通过StringBuilder的append方式的速度,要比直接对String使用“+”拼接的方式快的不是一点半点
那么,在实际开发中,对于需要多次或大量拼接的操作,在不考虑线程安全问题时,我们就应该尽可能使用StringBuilder进行append操作
除此之外,还有那些操作能够帮助我们提高字符串方面的运行效率呢?
StringBuilder空参构造器的初始化大小为16。那么,如果提前知道需要拼接String的个数,就应该直接使用带参构造器指定capacity,以减少扩容的次数(扩容的逻辑可以自行查看源代码)
/**
* Constructs a string builder with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuilder() {
super(16);
}
/**
* Constructs a string builder with no characters in it and an
* initial capacity specified by the {@code capacity} argument.
*
* @param capacity the initial capacity.
* @throws NegativeArraySizeException if the {@code capacity}
* argument is less than {@code 0}.
*/
public StringBuilder(int capacity) {
super(capacity);
}
5.new String问题
①new String创建了几个对象?
两个对象
一个对象是:new关键字在堆空间创建的;
另一个对象是:字符串常量池中的对象
②String str =new String(“a”) + new String(“b”) 会创建几个对象 ?
对象1: new StringBuilder()
对象2: new String(“a”)
对象3: 常量池中的"a"
对象4: new String(“b”)
对象5: 常量池中的"b"
StringBuilder 的 toString() 方法中有 new String(value, 0, count)
对象6 :new String(“ab”)
注意:此方法并不会在字符串常量池中创建
6.intern()
intern()方法是Java中的一个方法,用于将一个字符串对象添加到字符串常量池中,并返回该字符串对象的引用。如果该字符串对象已经存在于常量池中,则返回该对象的引用;否则,将该字符串对象添加到常量池中,并返回该对象的引用。
需要注意的是,intern()方法只能应用于字符串类型的变量,对于其他类型的变量会抛出异常。此外,由于常量池的空间是有限的制的,如果频繁地使用intern()方法,可能会导致常量池过大,从而影响程序性能。
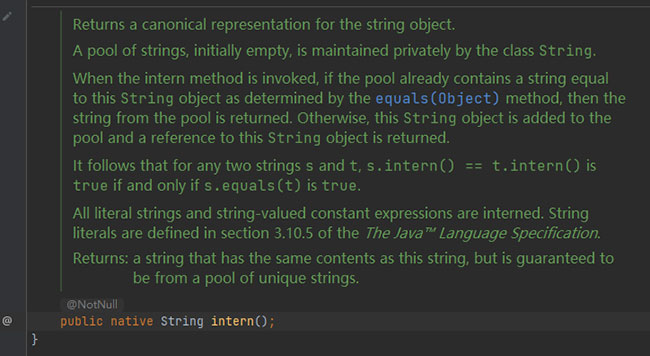
官方API文档:
public String intern()
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the class String.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
All literal strings and string-valued constant expressions are interned. String literals are defined in section 3.10.5 of the The Java™ Language Specification.
● Returns:
a string that has the same contents as this string, but is guaranteed to be from a pool of unique strings.
当调用intern方法时,如果池子里已经包含了一个与这个String对象相等的字符串,正如equals(Object)方法所确定的,那么池子里的字符串会被返回。否则,这个String对象被添加到池中,并返回这个String对象的引用。
由此可见,对于任何两个字符串s和t,当且仅当s.equals(t)为真时,s.intern() == t.intern()为真。
所有字面字符串和以字符串为值的常量表达式都是interned。
返回一个与此字符串内容相同的字符串,但保证是来自一个唯一的字符串池。
intern是一个native方法,调用的是底层C的方法
6.1代码演示
示例1
/**
* 如何保证变量s指向的是字符串常量池中的数据呢?
* 有两种方式:
* 方式一: String s = "hello";//字面量定义的方式
* 方式二: 调用intern()
* String s = new String("hello").intern();
* String s = new StringBuilder("hello").toString().intern();
*
*/
public class StringIntern {
public static void main(String[] args) {
String s = new String("1");
s.intern();//调用此方法之前,字符串常量池中已经存在了"1"
String s2 = "1";
System.out.println(s == s2);//jdk6:false jdk7/8:false
// 说一下上面为什么等于false
// 调用intern返回的是在字符串常量池中的地址,而new String() 会在heap创建一个对象,也会在字符串常量池创建一份 heap中指向字符串常量池
// 使用 == 比较是地址值 所以 s2是字符串常量池 而s是堆中地址值
String s3 = new String("1") + new String("1");//s3变量记录的地址为:new String("11")
//执行完上一行代码以后,字符串常量池中,是否存在"11"呢?答案:不存在!!
s3.intern();//在字符串常量池中生成"11"。如何理解:jdk6:创建了一个新的对象"11",也就有新的地址。
// jdk7:此时常量中并没有创建"11",而是创建一个指向堆空间中new String("11")的地址
String s4 = "11";//s4变量记录的地址:使用的是上一行代码代码执行时,在常量池中生成的"11"的地址
System.out.println(s3 == s4);//jdk6:false jdk7/8:true
}
}
示例2
public class StringIntern1 {
public static void main(String[] args) {
//StringIntern.java中练习的拓展:
String s3 = new String("1") + new String("1");//new String("11")
//执行完上一行代码以后,字符串常量池中,是否存在"11"呢?答案:不存在!!
String s4 = "11";//在字符串常量池中生成对象"11"
String s5 = s3.intern();
System.out.println(s3 == s4);//false
System.out.println(s5 == s4);//true
}
}
JDK1.6中,将这个字符串对象尝试放入串池。
如果串池中有,则并不会放入。返回已有的串池中的对象的地址
如果没有,会把此对象复制一份,放入串池,并返回串池中的对象地址
JDK1.7起,将这个字符串对象尝试放入串池。
如果串池中有,则并不会放入。返回已有的串池中的对象的地址
如果没有,则会把对象的引用地址复制一份,放入串池,并返回串池中的引用地址
6.2练习
示例1
public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b");//new String("ab")
//在上一行代码执行完以后,字符串常量池中并没有"ab"
String s2 = s.intern();//jdk6中:在串池中创建一个字符串"ab"
//jdk8中:串池中没有创建字符串"ab",而是创建一个引用,指向new String("ab"),将此引用返回
System.out.println(s2 == "ab");//jdk6:true jdk8:true
System.out.println(s == "ab");//jdk6:false jdk8:true
}
示例2
public static void main(String[] args) {
String s1 = new String("ab");//执行完以后,会在字符串常量池中会生成"ab"
// String s1 = new String("a") + new String("b");执行完以后,不会在字符串常量池中会生成"ab"
s1.intern();
String s2 = "ab";
System.out.println(s1 == s2);
}
6.3效率问题
/**
* 使用intern()测试执行效率:空间使用上
*
* 结论:对于程序中大量存在存在的字符串,尤其其中存在很多重复字符串时,使用intern()可以节省内存空间。
*/
public class StringIntern2 {
static final int MAX_COUNT = 1000 * 10000;
static final String[] arr = new String[MAX_COUNT];
public static void main(String[] args) {
Integer[] data = new Integer[]{1,2,3,4,5,6,7,8,9,10};
long start = System.currentTimeMillis();
for (int i = 0; i < MAX_COUNT; i++) {
// arr[i] = new String(String.valueOf(data[i % data.length]));
arr[i] = new String(String.valueOf(data[i % data.length])).intern();
}
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.gc();
}
}
// 运行结果
不使用intern:6346ms
使用intern:959ms
文章知识点与官方知识档案匹配,可进一步学习相关知识
转载请注明:可思数据 » 从JVM角度深入理解String
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


