
 |
为了处理大型数据集,分布式数据库引入了分区和分桶等策略。数据根据特定规则被划分为较小的单元,并分布在不同节点上,因此数据库可以执行并行处理,从而获得更高的性能和数据管理灵活性。
与许多数据库一样, Apache Doris将数据分片为分区,然后将分区进一步划分为存储桶。分区通常由时间或其他连续值定义。这允许查询引擎在查询期间通过修剪不相关的数据范围来快速定位目标数据。
另一方面,分桶根据一个或多个列的哈希值来分发数据,从而防止数据倾斜。
在2.1.0版本之前,有两种方法可以在 Apache Doris 中创建数据分区:
-
手动分区:用户在建表语句中指定分区,或者事后通过DDL语句进行修改。
-
动态分区:系统根据数据提取时间自动将分区维护在预定义范围内。
在 Apache Doris 2.1.0 中,我们引入了Auto Partition 功能,支持按 RANGE 或 LIST 对数据进行分区,在自动分区的基础上进一步增强了灵活性。
Doris 分区策略的演变
在数据分布的设计中,我们更加注重分区规划,因为分区列和分区间隔的选择很大程度上取决于实际的数据分布模式,而好的分区设计可以很大程度上提高表的查询和存储效率。
在 Doris 中,数据表被分层划分为 Partition 和 Bucket,同一个 Bucket 内的数据组成一个 Data Table ,它是 Doris 中最小的物理存储单元,用于数据复制、集群间数据调度、负载均衡等。
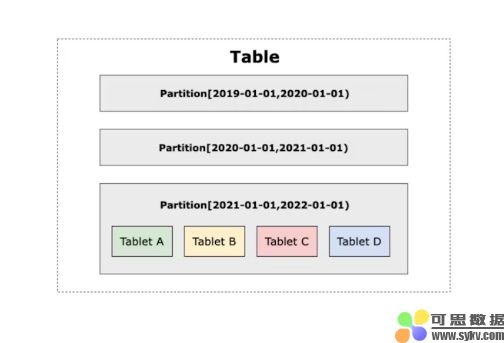
手动分区
Doris 允许用户通过 RANGE 和 LIST 手动创建数据分区。
对于日志、交易记录等带时间戳的数据,用户通常根据时间维度创建分区。以下是 CREATE TABLE 语句的示例:
CREATE TABLE IF NOT EXISTS example_range_tbl ( `user_id` LARGEINT NOT NULL COMMENT "User ID", `date` DATE NOT NULL COMMENT "Data import date", `timestamp` DATETIME NOT NULL COMMENT "Data import timestamp", `city` VARCHAR(20) COMMENT "Location of user", `age` SMALLINT COMMENT "Age of user", `sex` TINYINT COMMENT "Sex of user", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "Last visit date of user", `cost` BIGINT SUM DEFAULT "0" COMMENT "User consumption", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "Maximum dwell time of user", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "Minimum dwell time of user" ) ENGINE=OLAP AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`) PARTITION BY RANGE(`date`) ( PARTITION `p201701` VALUES LESS THAN ("2017-02-01"), PARTITION `p201702` VALUES LESS THAN ("2017-03-01"), PARTITION `p201703` VALUES LESS THAN ("2017-04-01"), PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01")) ) DISTRIBUTED BY HASH(`user_id`) BUCKETS 16 PROPERTIES ( "replication_num" = "1" );
该表按照数据导入日期date进行分区,预先创建了 4 个分区,每个分区内又根据user_id的 hash 值将数据划分为 16 个 bucket。
通过这种分区和分桶设计,当查询 2018 年以后的数据时,系统只需要扫描p2018分区。查询 SQL 如下所示:
mysql> desc select count() from example_range_tbl where date >= '20180101'; +--------------------------------------------------------------------------------------+ | Explain String(Nereids Planner) | +--------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS: | | count(*)[#11] | | PARTITION: UNPARTITIONED | | | | ...... | | | | 0:VOlapScanNode(193) | | TABLE: test.example_range_tbl(example_range_tbl), PREAGGREGATION: OFF. | | PREDICATES: (date[#1] >= '2018-01-01') | | partitions=1/4 (p2018), tablets=16/16, tabletList=561490,561492,561494 ... | | cardinality=0, avgRowSize=0.0, numNodes=1 | | pushAggOp=NONE | | | +--------------------------------------------------------------------------------------+
如果数据在各个分区之间分布不均匀,基于 hash 的分桶机制可以进一步根据user_id进行数据划分,避免查询和存储过程中部分机器负载不均衡。
但是在实际的业务场景中,一个集群可能有上万张表,手动去管理几乎是不可能的。
CREATE TABLE `DAILY_TRADE_VALUE` ( `TRADE_DATE` datev2 NOT NULL COMMENT 'Trade date', `TRADE_ID` varchar(40) NOT NULL COMMENT 'Trade ID', ...... ) UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`) PARTITION BY RANGE(`TRADE_DATE`) ( PARTITION p_200001 VALUES [('2000-01-01'), ('2000-02-01')), PARTITION p_200002 VALUES [('2000-02-01'), ('2000-03-01')), PARTITION p_200003 VALUES [('2000-03-01'), ('2000-04-01')), PARTITION p_200004 VALUES [('2000-04-01'), ('2000-05-01')), PARTITION p_200005 VALUES [('2000-05-01'), ('2000-06-01')), PARTITION p_200006 VALUES [('2000-06-01'), ('2000-07-01')), PARTITION p_200007 VALUES [('2000-07-01'), ('2000-08-01')), PARTITION p_200008 VALUES [('2000-08-01'), ('2000-09-01')), PARTITION p_200009 VALUES [('2000-09-01'), ('2000-10-01')), PARTITION p_200010 VALUES [('2000-10-01'), ('2000-11-01')), PARTITION p_200011 VALUES [('2000-11-01'), ('2000-12-01')), PARTITION p_200012 VALUES [('2000-12-01'), ('2001-01-01')), PARTITION p_200101 VALUES [('2001-01-01'), ('2001-02-01')), ...... ) DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10 PROPERTIES ( ...... );
在上面的例子中,数据按月分区。这需要数据库管理员 (DBA) 每月手动添加新分区并定期维护表架构。想象一下实时数据处理的情况,您可能需要每天甚至每小时创建分区,手动执行此操作不再是一种选择。这就是我们引入动态分区的原因。
动态分区
通过动态分区,只要用户指定分区单位、历史分区数和未来分区数,Doris 就会自动创建和回收数据分区。此功能依赖于 Doris Frontend 上的固定线程。它会不断轮询并检查是否有新的分区需要创建或旧分区需要回收,并更新表的分区模式。
这是按天分区的表的 CREATE TABLE 语句示例。start 和end参数分别设置start -7和3 ,这意味着将预先创建接下来 3 天的数据分区,并回收超过 7 天的历史分区。
CREATE TABLE `DAILY_TRADE_VALUE` ( `TRADE_DATE` datev2 NOT NULL COMMENT 'Trade date', `TRADE_ID` varchar(40) NOT NULL COMMENT 'Trade ID', ...... ) UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`) PARTITION BY RANGE(`TRADE_DATE`) () DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10 PROPERTIES ( "dynamic_partition.enable" = "true", "dynamic_partition.time_unit" = "DAY", "dynamic_partition.start" = "-7", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.buckets" = "10" );
随着时间的推移,表将始终维护[current date - 7, current date + 3]范围内的分区。动态分区对于实时数据提取场景特别有用,例如当 ODS(操作数据存储)层直接从 Kafka 等外部源接收数据时。
start和end参数定义了分区的固定范围,允许用户只管理此范围内的分区。但是,如果用户需要包含更多历史数据,则必须调高start ,这可能会导致集群中不必要的元数据开销。
因此,在应用动态分区时,需要在元数据管理的便捷性和效率之间进行权衡。
开发人员的话
随着业务复杂性的增加,动态分区变得不够用,因为:
- 仅支持按 RANGE 进行分区,不支持按 LIST 进行分区。
- 它只能应用于当前的真实世界的时间戳。
- 它仅支持单个连续的分区范围,并且不能容纳该范围之外的分区。
考虑到这些功能限制,我们开始规划一种新的分区机制,既可以自动化分区管理,又可以简化数据表的维护。
我们认为理想的分区实现应该:
- 省去了建表后手动创建分区的麻烦;
- 能够在相应的分区中容纳所有摄取的数据。
前者代表自动化,后者代表灵活性,实现二者的本质都是将分区创建与实际数据关联起来。
然后我们开始思考以下问题:如果我们等到数据被提取后再创建分区,而不是在创建表时或通过定期轮询来创建分区,会怎么样?我们可以定义“数据到分区”的映射规则,以便在数据到达后创建分区,而不是预先构建分区分布。
与手动分区相比,整个过程将完全自动化,无需人工维护。与动态分区相比,它可以避免出现未使用的分区或需要但不存在的分区。
自动分区
在Apache Doris 2.1.0中,我们把上述计划变成了现实。在数据摄取过程中,Doris 根据配置的规则创建数据分区。负责数据处理和分发的 Doris Backend 节点会在执行计划的 DataSink 操作符中尝试为每一行数据找到合适的分区。它不再过滤掉不适合任何现有分区的数据或为此报告错误,而是自动为所有摄取的数据生成分区。
按范围自动分区
RANGE 的 Auto Partition 提供了基于时间维度的优化分区方案,在参数配置上比 Dynamic Partition 更加灵活,语法如下:
AUTO PARTITION BY RANGE (FUNC_CALL_EXPR) () FUNC_CALL_EXPR ::= DATE_TRUNC ( <partition_column>, '<interval>' )
上面的<partition_column>是分区列(即分区所依据的列)。 <interval>指定分区单位,也就是希望的每个分区的宽度。
例如分区列为k0 ,按月份分区,则分区语句为AUTO PARTITION BY RANGE (DATE_TRUNC(k0, 'month')) ,对于所有导入的数据,系统会调用DATE_TRUNC(k0, 'month')计算分区的左端点,然后再加一个interval计算分区的右端点。
现在,我们可以将自动分区应用于上一节动态分区中介绍的DAILY_TRADE_VALUE表。
CREATE TABLE DAILY_TRADE_VALUE ( `TRADE_DATE` DATEV2 NOT NULL COMMENT 'Trade Date', `TRADE_ID` VARCHAR(40) NOT NULL COMMENT 'Trade ID', ...... ) AUTO PARTITION BY RANGE (DATE_TRUNC(`TRADE_DATE`, 'month')) () DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10 PROPERTIES ( ...... );
导入一些数据后,我们得到的分区如下:
mysql> show partitions from DAILY_TRADE_VALUE; Empty set (0.10 sec) mysql> insert into DAILY_TRADE_VALUE values ('2015-01-01', 1), ('2020-01-01', 2), ('2024-03-05', 10000), ('2024-03-06', 10001); Query OK, 4 rows affected (0.24 sec) {'label':'label_2a7353a3f991400e_ae731988fa2bc568', 'status':'VISIBLE', 'txnId':'85097'} mysql> show partitions from DAILY_TRADE_VALUE; +-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables | +-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | 588395 | p20150101000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2015-01-01]; ..types: [DATEV2]; keys: [2015-02-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 588437 | p20200101000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2020-01-01]; ..types: [DATEV2]; keys: [2020-02-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 588416 | p20240301000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-01]; ..types: [DATEV2]; keys: [2024-04-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | +-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ 3 rows in set (0.09 sec)
如图所示,会自动为导入的数据创建分区,并且不会创建超出现有数据范围的分区。
按列表自动分区
LIST 自动分区是指按照非时间维度(例如region 、 department对数据进行分片,弥补了动态分区不支持 LIST 数据分区的缺陷。
RANGE 的 Auto Partition 提供了基于时间维度的优化分区方案,在参数配置上比 Dynamic Partition 更加灵活,语法如下:
AUTO PARTITION BY LIST (`partition_col`) ()
这是使用city作为分区列的 LIST 自动分区的示例:
mysql> CREATE TABLE `str_table` ( -> `city` VARCHAR NOT NULL, -> ...... -> ) -> DUPLICATE KEY(`city`) -> AUTO PARTITION BY LIST (`city`) -> () -> DISTRIBUTED BY HASH(`city`) BUCKETS 10 -> PROPERTIES ( -> ...... -> ); Query OK, 0 rows affected (0.09 sec) mysql> insert into str_table values ("Denver"), ("Boston"), ("Los_Angeles"); Query OK, 3 rows affected (0.25 sec) mysql> show partitions from str_table; +-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables | +-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | 589685 | pDenver7 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Denver]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 589643 | pLos5fAngeles11 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Los_Angeles]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 589664 | pBoston8 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Boston]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | +-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ 3 rows in set (0.10 sec)
在插入丹佛、波士顿、洛杉矶等城市的数据后,系统会自动根据城市名创建相应的分区。以前这种自定义分区只能通过手动 DDL 语句来实现。这就是 LIST 的 Auto Partition 简化数据库维护的方式。
提示和说明
手动调整历史分区
对于同时接收实时数据和偶尔的历史更新的表,由于自动分区不会自动回收历史分区,我们推荐两种选择:
-
使用自动分区,它将自动为偶尔的历史数据更新创建分区。
-
使用自动分区并手动创建一个
LESS THAN分区来容纳历史更新。这可以更清晰地区分历史数据和实时数据,并使数据管理更加容易。
mysql> CREATE TABLE DAILY_TRADE_VALUE -> ( -> `TRADE_DATE` DATEV2 NOT NULL COMMENT 'Trade Date', -> `TRADE_ID` VARCHAR(40) NOT NULL COMMENT 'Trade ID' -> ) -> AUTO PARTITION BY RANGE (DATE_TRUNC(`TRADE_DATE`, 'DAY')) -> ( -> PARTITION `pHistory` VALUES LESS THAN ("2024-01-01") -> ) -> DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10 -> PROPERTIES -> ( -> "replication_num" = "1" -> ); Query OK, 0 rows affected (0.11 sec) mysql> insert into DAILY_TRADE_VALUE values ('2015-01-01', 1), ('2020-01-01', 2), ('2024-03-05', 10000), ('2024-03-06', 10001); Query OK, 4 rows affected (0.25 sec) {'label':'label_96dc3d20c6974f4a_946bc1a674d24733', 'status':'VISIBLE', 'txnId':'85092'} mysql> show partitions from DAILY_TRADE_VALUE; +-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables | +-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | 577871 | pHistory | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [0000-01-01]; ..types: [DATEV2]; keys: [2024-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 577940 | p20240305000000 | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-05]; ..types: [DATEV2]; keys: [2024-03-06]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 577919 | p20240306000000 | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-06]; ..types: [DATEV2]; keys: [2024-03-07]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | +-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ 3 rows in set (0.10 sec)
NULL 分区
通过 LIST 自动分区,Doris 支持将 NULL 值存储在 NULL 分区中。例如:
mysql> CREATE TABLE list_nullable -> ( -> `str` varchar NULL -> ) -> AUTO PARTITION BY LIST (`str`) -> () -> DISTRIBUTED BY HASH(`str`) BUCKETS auto -> PROPERTIES -> ( -> "replication_num" = "1" -> ); Query OK, 0 rows affected (0.10 sec) mysql> insert into list_nullable values ('123'), (''), (NULL); Query OK, 3 rows affected (0.24 sec) {'label':'label_f5489769c2f04f0d_bfb65510f9737fff', 'status':'VISIBLE', 'txnId':'85089'} mysql> show partitions from list_nullable; +-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables | +-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ | 577297 | pX | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: [NULL]; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 577276 | p0 | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: []; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | | 577255 | p1233 | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: [123]; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL | +-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+ 3 rows in set (0.11 sec)
但是,按范围自动分区不支持 NULL 分区,因为 NULL 值将存储在最小的LESS THAN分区中,无法可靠地确定其适当的范围。如果自动分区要创建一个范围为 (-INFINITY, MIN_VALUE) 的 NULL 分区,则存在该分区在生产中被无意删除的风险,因为 MIN_VALUE 边界可能无法准确表示预期的业务逻辑。
概括
自动分区涵盖了动态分区的大部分用例,同时引入了预先定义分区规则的好处。一旦定义了规则,大部分分区创建工作将由 Doris 自动处理,而不是 DBA。
在使用自动分区之前,了解相关的限制非常重要:
-
LIST 自动分区支持基于多列进行分区,但每个自动创建的分区仅包含一个值,并且分区名称的长度不能超过 50 个字符。请注意,分区名称遵循特定的命名约定,这对元数据管理有特殊影响。这意味着并非所有 50 个字符的空间都由用户支配。
-
按范围自动分区仅支持单个分区列,且该分区列类型必须是DATE或DATETIME 。
-
LIST 自动分区支持NULLABLE分区列和插入 NULL 值。RANGE 自动分区不支持 NULLABLE 分区列。
-
Apache Doris 2.1.3 之后,不建议将自动分区与动态分区结合使用。
性能比较
自动分区和动态分区的主要功能差异在于分区的创建和删除、支持的分区类型以及它们对导入性能的影响。
动态分区使用固定线程定期创建和回收分区,仅支持按 RANGE 分区,而自动分区则同时支持按 RANGE 和 LIST 分区,在数据采集过程中根据特定规则自动按需创建分区,提供更高水平的自动化和灵活性。
动态分区不会降低数据导入速度,而自动分区会先检查现有分区,然后按需创建新分区,因此会造成一定的时间开销。下面我们来展示一下性能测试结果。

自动分区:摄取工作流程
这部分主要讲解如何通过 Auto Partition 机制实现数据导入,以Stream Load为例。当 Doris 发起数据导入时,其中一个 Doris Backend 节点会充当 Coordinator 的角色,负责初始的数据处理工作,然后将数据分发到合适的 BE 节点(Executors)执行。

在Coordinator执行管道的最终Datasink Node中,数据需要被路由到正确的分区、bucket以及Doris Backend节点位置,才能够被成功传输和存储。
为了实现此数据传输,协调器节点和执行器节点建立通信渠道:
- 发送端称为Node Channel。
- 接收端称为“平板电脑通道”。
自动分区在确定数据正确分区的过程中发挥作用的方式如下:
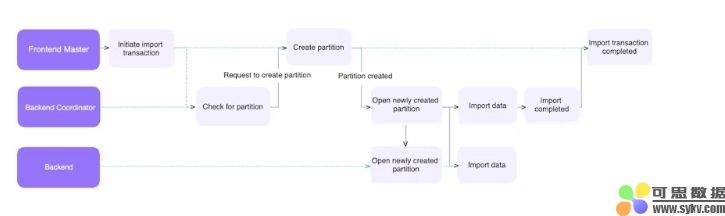
以前,如果没有 Auto Partition,当表没有所需的分区时,Doris 中的行为是 BE 节点累积错误,直到报告DATA_QUALITY_ERROR 。现在,启用 Auto Partition 后,将向 Doris Frontend 发起请求,以动态创建必要的分区。分区创建事务完成后,Doris Frontend 会响应 Coordinator,然后 Coordinator 打开相应的通信通道(Node Channel 和 Tablets Channel)以继续数据提取过程。这对用户来说是一种无缝的体验。
在实际集群环境中,Coordinator 等待 Doris Frontend 完成分区创建所花费的时间可能会产生很大的开销。这是由于 Thrift RPC 调用固有的延迟,以及高负载条件下 Frontend 上的锁争用。
为了提高 Auto Partition 中的数据导入效率,Doris 实现了批处理功能,大大减少了对 FE 的 RPC 调用次数。这为数据写入操作带来了显着的性能提升。
请注意,当 FE Master 完成分区创建事务时,新分区将立即可见。但是,如果导入过程最终失败或被取消,则不会自动回收创建的分区。
自动分区性能
我们测试了 Doris 中自动分区的性能和稳定性,涵盖了不同的用例:
案例 1 :1 个前端 + 3 个后端;6 个随机生成的数据集,每个数据集有 1 亿行和 2,000 个分区;将 6 个数据集同时导入到 6 个表中
-
目标:评估自动分区在高压下的性能并检查是否有任何性能下降。
-
效果:自动分区带来的平均性能损失小于5% ,且所有导入事务均稳定运行。
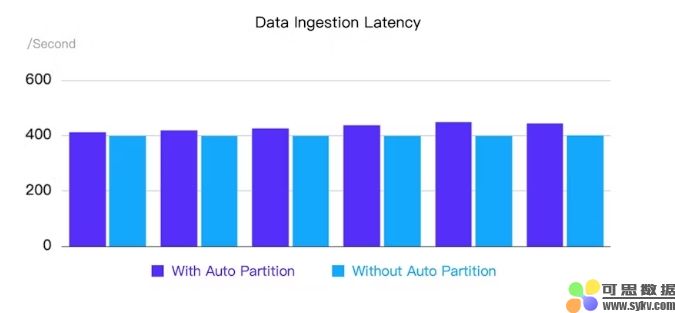
案例 2 :1 个前端 + 3 个后端;通过 Routine Load 每秒从 Flink 中提取 100 行数据;分别使用 1、10 和 20 个并发事务(表)进行测试
-
目标:识别在不同并发级别下自动分区可能出现的任何潜在数据积压问题。
-
结果:无论是否启用自动分区,数据提取均成功,并且在所有测试的并发级别中均没有任何背压问题,即使在 CPU 利用率接近 100% 时有 20 个并发事务也是如此。
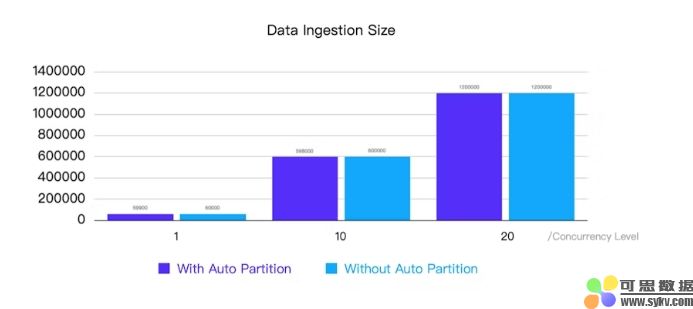
总结这些测试的结果,启用自动分区对数据提取性能的影响很小。
结论和未来计划
Auto Partition 自 Apache Doris 2.1.0 以来简化了 DDL 和分区管理。它在大规模数据处理中非常有用,并且使用户可以轻松地从其他数据库系统迁移到 Apache Doris。此外,我们致力于扩展自动分区的功能以支持更复杂的数据类型。
RANGE 的自动分区计划:
-
支持数值;
-
允许用户指定分区范围的左边界和右边界。
按 LIST 自动分区的计划:
- 允许根据特定规则将多个值合并到同一个分区。
转载请注明:可思数据 » Apache Doris 中数据分片向自动化和灵活性的演变
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


